






Mengenal Decision Tree
} Decision tree adalah struktur flowchart yang menyerupai tree
(pohon), dimana setiap simpul internal menandakan suatu tes pada atribut,
setiap cabang merepresentasikan hasil tes, dan simpul daun merepresentasikan
kelas atau distribusi kelas. Alur pada
decision tree di telusuri dari simpul akar ke simpul daun yang memegang
prediksi. (Han, J., & Kamber, M. (2006). Data Mining Concept and Tehniques.
San Fransisco: Morgan Kauffman.)
} Sebuah pohon keputusan adalah sebuah struktur yang dapat
digunakan untuk membagi kumpulan data yang besar menjadi himpunan-himpunan record
yang lebih kecil dengan menerapkan serangkaian aturan keputusan. Dengan
masing-masing rangkaian pembagian, anggota himpunan hasil menjadi mirip satu
dengan yang lain (Berry & Linoff, 2004).
Decision Tree
} Pohon keputusan :
metode yang umum digunakan untuk melakukan klasifikasi pada data mining.
} Klasifikasi : Teknik
menemukan kumpulan pola atau fungsi yang mendeskripsikan serta memisahkan kelas
data yang satu dengan yang lainnya.
} Tujuan Klasifikasi :
Untuk menyatakan objek tersebut masuk pada kategori tertentu.
} Pohon keputusan mampu melakukan klasifikasi sekaligus menunjukkan
hubungan antar atributnya.
Algoritma c4.5
} Algoritma C4.5 dapat menangani data numerik dan diskret.
} Algoritma C.45 menggunakan rasio perolehan (gain ratio). Sebelum
menghitung rasio perolehan, perlu dilakukan perhitungan nilai informasi dalam
satuan bits dari suatu kumpulan objek, yaitu dengan menggunakan konsep entropi.
Konsep Entropy
} Entropy(S) : perkiraan
jumlah bit yang dibutuhkan untuk mengekstrak suatu kelas (+ atau -) dari
sejumlah data acak pada ruang sampel S.
} Entropy :
kebutuhan bit untuk menyatakan suatu kelas. Semakin kecil nilai Entropy, maka
Entropy akan semakin digunakan dalam mengekstrak kelas.
} Entropi digunakan untuk mengukur ketidakaslian S.
Besarnya Entropy pada ruang sampel S
dimana:
} S : ruang (data) sampel yang digunakan untuk pelatihan
} P+ :
jumlah yang bersolusi positif atau mendukung pada data sampel untuk kriteria
tertentu
} P- :
jumlah yang bersolusi negatif atau tidak mendukung pada data sampel untuk kriteria
tertentu.
Konsep Gain
} Gain (S,A) merupakan Perolehan informasi dari atribut A relative
terhadap output data S.
} Perolehan informasi dalam Gain didapat dari output data (S) yang
dikelompokkan berdasarkan atribut (A)
} Dinotasikan dengan gain (S,A).

dimana:
} A : Atribut
} S : Sampel
} n : Jumlah
partisis himpunan atribut A
} |Si| : Jumlah sampel pada pertisi ke –i
|S| :
Jumlah sampel dalam S 
Contoh Kasus Dan Teknik Penyelesaian Masalah
} Masalah yang akan di analisis : mengklasifikasikan calon
pendaftar di suatu STMIK xxx dalam hal pemilihan program studi Sistem Komputer
Atau Sistem Informasi.
} Data yang
digunakan : nama mahasiswa, minat
calon mahasiswa, asal sekolah, jenis kelamin, hobi.
} Data selajutnya akan dilakukan pra-proses untuk menghasikan data
kasus yang siap dibentuk untuk menjadi sebuah pohon keputusan. Data yang tidak lengkap disebabkan
karena ada data yang kosong atau atribut yang salah.
} Berdasarkan program studi strata 1, ada sebagian atribut yag
tidak diperlukan sehingga proses Data Preprocessing perlu dilakukan.
Langkah dalam Data Preprocessing
1. Data Selection
} Data minat calon mahasiswa/i baru yang mendaftar ke STMIK xxx berdasarkan program studi strata 1
tersebut akan menjadi data kasus dalam proses operasional data mining.
} Dari data yang ada, kolom yang diambil sebagai atribut keputusan
adalah hasil, sedangkan kolom yang diambil atribut penentuan
dalam pembentukan pohon keputusan adalah :
} a. Nama Mahasiswa, b.
Minat calon mahasiswa, c. Asal sekolah, d. Jenis kelamin, e. Hobi
2. Data Preprocessing / Data
Cleaning
} Data Cleaning diterapkan untuk menambahkan isi atribut
yang hilang atau kosong dan merubah data yang tidak konsisten.
3. Data Transformation
} Dalam proses ini, data ditransferkan ke dalam bentuk yang sesuai
untuk proses data mining.
4. Data Reduction
} Reduksi data dilakukan dengan menghilangkan atribut yang tidak
diperlukan sehingga ukuran dari database menjadi kecil dan hanya
menyertakan atribut yang diperlukan dalam proses data mining, karena akan lebih efisien terhadap data yang lebih
kecil.
} Masalah klasifikasi berakhir dengan dihasilkan sebuah
pengetahuan yang dipresentasikan dalam bentuk diagram yang biasa disebut pohon
keputusan (decision tree).
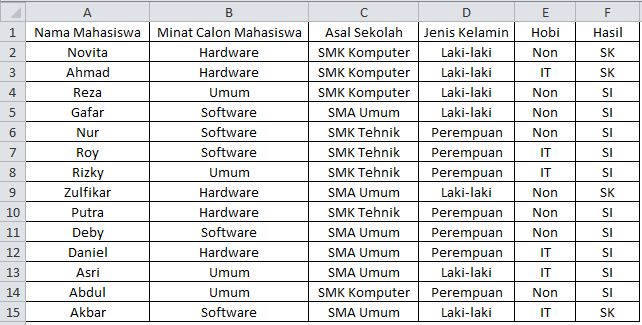
Keterangan :
Asal Sekolah
} SMK Komputer :
Teknik Komputer Dan Jaringan, Multimedia, dan Rekayasa perangkat lunak
} Sekolah umum : SMA dari jurusan IPA, IPS
} SMK Teknik : Teknik
Elektro, Teknik Mesin, Teknik Listrik dll
Nilai Atribut
} SI : Sistem Informasi
} SK : Sistem Komputer.

Penjelasan
} Jumlah seluruh hasil = 14
} Jumlah seluruh SK pada hasil = 4
} Jumlah seluruh SI pada hasil = 10
Entropy Minat Calon
Mahasiswa
Nilai atribut “Hardware”
= ((-3/5) * Log 2 (3/5)) + ((-2/5)
* log 2 (2/5))
=0.970950594
Nilai atribut “Software”
= ((-1/5) * Log 2 (1/5)) + ((-4/5)
* log 2 (4/5))
= 0.721928095
Nilai atribut “Umum”
= ((-0/4) * Log 2 (0/4)) + ((-4/4) * log2 (4/4))
= 0
Penjelasan
} Jumlah seluruh hardware =
5
} Jumlah seluruh hardware pada SK =
3
} Jumlah seluruh hardware pada SI =
10
} Jumlah seluruh software =
5
} Jumlah seluruh software pada SK =
1
} Jumlah seluruh software pada SI =
4
} Jumlah seluruh umum =
4
} Jumlah seluruh umum pada SK =
0
} Jumlah seluruh umum pada SI =
4
Entropy Histori Pendidikan (Asal Sekolah)
Nilai atribut “SMK Komputer”
= ((-2/4) * Log 2 (2/4)) + ((-2/4)
* log 2 (2/4)) = 1
Nilai atribut “SMK Teknik”
= ((-0/4) * Log 2 (0/4)) + ((-4/4)
* log 2 (4/4)) = 0
Nilai atribut “SMA Umum”
= ((-2/6) * Log 2 (2/6)) + ((-4/6)
* log 2 (4/6))
= 0.918295834
Penjelasan
} Jumlah seluruh SMK Komputer =
4
} Jumlah seluruh SMK Komputer pada SK = 2
} Jumlah seluruh SMK Komputer pada SI = 2
} Jumlah seluruh SMK Tehnik =
4
} Jumlah seluruh SMK Tehnik pada SK = 0
} Jumlah seluruh SMK Tehnik pada SI = 4
} Jumlah seluruh SMK umum =
6
} Jumlah seluruh SMK umum pada SK =
2
} Jumlah seluruh SMK umum pada SI =
4
Entropy Hobi
Nilai atribut “IT”
= ((-4/6) * Log 2 (4/6)) + ((-2/6)
* log 2 (2/6))
= 0.918295834
Nilai atribut “Non IT”
= ((-2/8) * Log 2 (2/8)) + ((-6/8)
* log 2 (6/8))
= 0.811278124
Penjelasan
} Jumlah seluruh IT =
6
} Jumlah seluruh IT pada SK =
2
} Jumlah seluruh IT pada SI =
4
} Jumlah seluruh Non IT =
8
} Jumlah seluruh Non IT pada SK =
2
} Jumlah seluruh Non Itpada SI =
6
Entropy Jenis Kelamin
Nilai atribut “Laki-laki”
= ((-4/7)) * Log 2 (4/7)) + ((-3/7) * log 2 (3/7))
= 0.985228136
Nilai atribut “Perempuan”
= ((-0/7) * Log 2 (0/7) + ((-7/7) * log 2 (7/7))
= 0
Penjelasan
} Jumlah seluruh Laki-laki =
7
} Jumlah seluruh Laki-laki pada SK = 4
} Jumlah seluruh Laki-laki pada SI = 3
} Jumlah seluruh Perempuan =
7
} Jumlah seluruh Perempuan pada SK = 0
} Jumlah seluruh Perempuan pada SI = 7
Nilai Gain
Nilai Gain Minat Calon Mahasiswa
= 0.863120569 – ( ((5/14)*0.970950594))
+
((5/14)*0.721928095)) +
((4/14)*0)) )
= 0.258521037
Nilai Gain Histori
Pendidikan
= 0.863120569 – ( ((4/14)*1))
+ ((4/14)*0)) + ((6/14)*0.918295834)) )
= 0.183850925
Nilai Gain Hobi
= 0.863120569 – ( ((6/14)*0.918295834))
+ ((8/14)*0)) )
= 0.005977711
Nilai Gain Jenis Kelamin
= 0.863120569 – ( ((7/14)*
0.985228136)) + ((7/14)*0)) )
= 0.005977711










Basis pengetahuan/rule yang
terbentuk
1. Jika Jenis Kelamin = Perempuan maka Hasil =
Sistem Informasi
2. Jika Jenis Kelamin = Laki-laki, Minat
Calon = Hardware maka
Hasil = Sistem Komputer
3. Jika Jenis Kelamin = Laki-laki, Minat
Calon = Umum maka
Hasil = Sistem Informasi
4. Jika Jenis Kelamin = Laki-laki, Minat
Calon = Software, Hobi = IT maka
Hasil = Sistem Komputer
5. Jika Jenis Kelamin = Laki-laki, Minat
Calon = Software, Hobi
= Non IT maka Hasil =
Sistem Informasi
Referensi
} STMIK Pelita Nusantara Medan 2015 : Data Mining
} Aprilia, Baskoro,
Ambarwati, & Wicaksono :
Belajar Data Mining dengan RapidMiner.
Jakarta. April 2013

